
Por Joan López
La incertidumbre de una crisis como la que estamos viviendo se ha convertido en una ventana de oportunidad para que las soluciones tecnológicas a problemas complejos reemplacen la toma de decisiones de política pública (Morozov, 2020). En medio de la crisis social y económica provocada por el Covid-19, el Departamento Nacional de Planeación, en tan solo dos semanas, montó un sistema de transferencias no condicionadas para 3 millones de personas (DNP, 2020a). El programa se denominó Ingreso Solidario.
El programa ha sido muy criticado por los errores en sus bases de datos. Sin embargo, lo sucedido requiere un análisis más de fondo. Debemos preguntarnos qué tipo de política social es la que Ingreso Solidario representa y cuáles son sus problemas para la construcción de una sociedad más justa.
Desde los 90, la política social colombiana está basada en focalizar los recursos en las personas en condición de pobreza (Mares & Carnes, 2009). Es decir, el Estado creó mecanismos para “buscar a las personas pobres” y llevarles los limitados recursos disponibles. En este contexto, apareció el Sistema de Posibles Beneficios de Programas Sociales (Sisbén) como principal instrumento para focalizar la asistencia social. Este sistema califica a las personas con puntajes de 0 a 100 en términos de “prosperidad” (Mcgee, 1999).
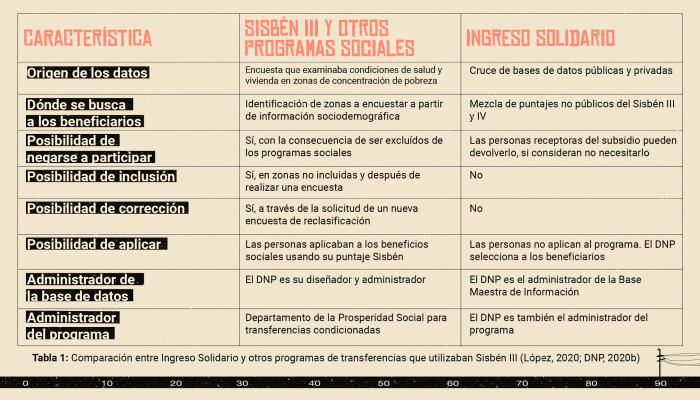
Para entender la diferencia entre Ingreso Solidario y la asistencia social tradicional, debemos entender cómo funcionaba en términos de datos la asignación de un beneficio social hasta la tercera versión del Sisbén (Ver Tabla 1).
La dinámica para los primeros programas sociales focalizados se valía de un examen de las condiciones de cada hogar en el que las personas eran actores en la producción de los datos. El puntaje Sisbén surgió de un esfuerzo institucional de salir a “buscar” a las personas en vulnerabilidad a través de encuestas en zonas empobrecidas que terminaban en una puntuación. De acuerdo a esa calificación las personas podían solicitar los programas sociales para los que eran elegibles de acuerdo a los límites establecidos por cada entidad.
El Ingreso Solidario cambió la dinámica de la relación entre los datos utilizados por el Estado para asignar un beneficio y la participación de las personas en el sistema. En medio de la crisis del COVID-19, la respuesta fue un experimento que implicaba utilizar la mayor cantidad de datos posibles para “encontrar” a las personas que “necesitaban”, pero que no recibían programas sociales. El DNP construyó una nueva Base Maestra de Información (BMI), en la que se mezclaron registros administrativos de todo tipo. Se reunieron datos que se habían recogido con muchos propósitos, que son administrados por actores tanto privados como públicos, que tienen diversos niveles de calidad y que mucha de la gente calificada desconocía. En otras palabras, ya no se trata de “encontrar” a las personas en condición de vulnerabilidad en las zonas geográficas afectadas por la pobreza, sino de “aprovechar” los datos personales que vamos dejando en nuestra interacción con diferentes instituciones.

El experimento, a pesar de que se ha querido mostrar como un éxito, terminó abriendo la caja de pandora de la institucionalidad colombiana y mostrando su dependencia del sector privado. El DNP publicó la lista de personas beneficiarias y un manual de operación. En los días siguientes, muchas personas denunciaron errores de inclusión de cédulas inexistentes, vencidas, repetidas y con datos incorrectos (DNP, 2020a).
En respuesta, el DNP desmontó la base de datos y entregó la lista de cédulas a la Registraduría para una depuración, que resultó en cerca de 17.000 registros con esos problemas (El Tiempo, 2020). Después del incidente, aseguró que los errores no importaban, ya que los bancos verifican la identidad antes de hacer una transacción. Así, para el caso de las personas no bancarizadas se utilizaron nuevas bases de datos del INPEC y Medicina Legal para excluir fallecidos recientes. Este acontecimiento, no obstante, mostró que los registros del Estado tienen serios problemas de calidad y la confusión en la comunicación pública del programa pues el uso de estas bases de datos no está en el manual de operación pero sí en una presentación del DNP ante el Congreso.
¿Cuántas personas fueron injustamente excluidas en los cruces de bases de datos de diversas calidades? Quizás nunca lo sabremos. Lo que sí podemos analizar es la narrativa de política social que se esconde detrás de Ingreso Solidario. El gobierno, en su respuesta a la crisis del COVID-19, está usando las bases de datos para evitar una discusión política que implica decidir quiénes deben ser elegibles para una redistribución social en un momento de crisis. A pesar del afán de la emergencia, no podemos aceptar que estos sistemas nos quiten la posibilidad de discutir quiénes se pueden quedar fuera, cuáles son las consecuencias para la vida de las personas excluidas y qué alternativas podemos ofrecerles.
La identificación de personas beneficiarios en sociedades como las nuestras con altos niveles de pobreza, desempleo, informalidad y desigualdad son resultados arbitrarios de mecanismos basados en datos. Esa focalización limitada implica una forma de violencia para las personas que quedan por fuera (Gupta, 2012). Especialmente en momentos de crisis. ¿Por qué el DNP trazó una línea entre los posibles beneficiarios en una pandemia en 8,7 millones de familias con 17 millones en una situación vulnerable? Estas preguntas requieren una amplia discusión política que dependen de ejercicios de transparencia y participación, no de estudios secretos.

En este caso, tenemos un Estado que le quita la capacidad de actuar a las personas para exigir sus derechos sociales y participar activamente en la identidad que se les quiere imponer. Los datos no son perfectas representaciones de la realidad, sino que están mediados en su producción por la acción política. La manera en la que se ha desplegado Ingreso Solidario imposibilita a las personas de exigir sus derechos. Difícilmente podrán pedir que se corrija información en el mar de bases de datos usadas, conocer los procedimientos de decisión y reclamar por el resultado. Mucho menos les permite participar activamente en la construcción de una política social que, aun en momentos de emergencia, les dé capacidad de actuar.
Los burócratas se están escondiendo detrás de los datos y las soluciones tecnológicas para negarle la capacidad de actuar a las personas de participar en las decisiones del Estado, de reclamar ante injusticias y de reivindicar la protección de sus derechos sociales. De ahí, que llamen “mitos” a las denuncias ciudadanas o nieguen la capacidad de autodeterminación de las personas que informan no necesitar el subsidio argumentando que las bases de datos no mienten y que “no hay errores” (DNP, 2020a). En otras palabras, estamos ante a un gobierno arrogante que dice unilateralmente quién necesita ayuda, mientras las personas no tienen voz. Tanto así que poseen la verdad de por qué protestan las personas que piden garantías de subsistencia: son “manipuladas” o “quieren saltar la fila” (RCN Radio, 2020). En resumen, Ingreso Solidario es una forma de usar tecnologías y datos para evitar discusiones políticas.

En conclusión, Ingreso Solidario es una muestra del preocupante futuro de la política social en la que las personas tienen cada vez menos mecanismos para exigir sus derechos frente al Estado. También es la evidencia de que los “verdaderos” beneficiarios saldrán de los datos que vamos dejando inadvertidamente y no de un ejercicio de ciudadanía activa. Nos venden el programa como una innovación, pero no ha sido más que un gran experimento para poner a rodar una política social altamente dependiente de la tecnología. Con ella, el Estado va determinar automáticamente, a través de datos de terceros y de manera poco transparente, a las personas “merecedoras” de beneficios sociales. Una política pensada no para incluir más personas, sino para eliminar los “errores de inclusión o colados”, en el que la ciudadanía no tendrá posibilidad de demandar. En otras palabras, estamos ante un sistema que usará la mayor cantidad de datos posibles para encontrar a la menor cantidad de personas beneficiarias posibles.
Si quieres entender mejor de qué se trata este caso, te invitamos a revisar nuestros blogs explicativos:
¡Cúlpelos a ellos! La vigilancia sobre las personas en vulnerabilidad
¡No pueden ser tantos pobres! La exclusión de personas beneficiarias con analítica de datos.
Para saber más sobre esta investigación, puedes revisar: Experimentando con la pobreza: El SISBÉN y los proyectos de analítica de datos en Colombia.
O puedes descargar el informe directamente aquí
Consulta los documentos fuente de la investigación en este link.